Санкт-Петербург
Программное обеспечение
 0 проектов
0 проектов





Хочу поделиться с Вами своим проектом. Это программа по распознаванию соционического типа на базе нейросетей именуемая СОЦИОМЕТР 15-100 и СОЦИОМЕТР-45-100
https://isocionics.com/projects/sociometr15
1) Найти свою вторую половинку https://isocionics.com/library/shulman

2) Понять, как строить отношения с окружающими
https://isocionics.com/library/intertype/table_intro
3) Понимать свои сильные и слабые стороны
https://isocionics.com/library/aushra/model_a

4) Понимать чего можно ждать от людей, а чего нельзя
https://isocionics.com/library/types

5) Понять, в какой сфере деятельности кто лучше, и командообразование
https://isocionics.com/library/meged/target_dyads

6) Исследовать связь социотипа с рекламными предпочтениями(Важно для сфер рекламы!)

7) Все вышеупомянутые пункты можно объединить в единую формулировку: «Соционика применима везде, где присущ человеческий фактор»

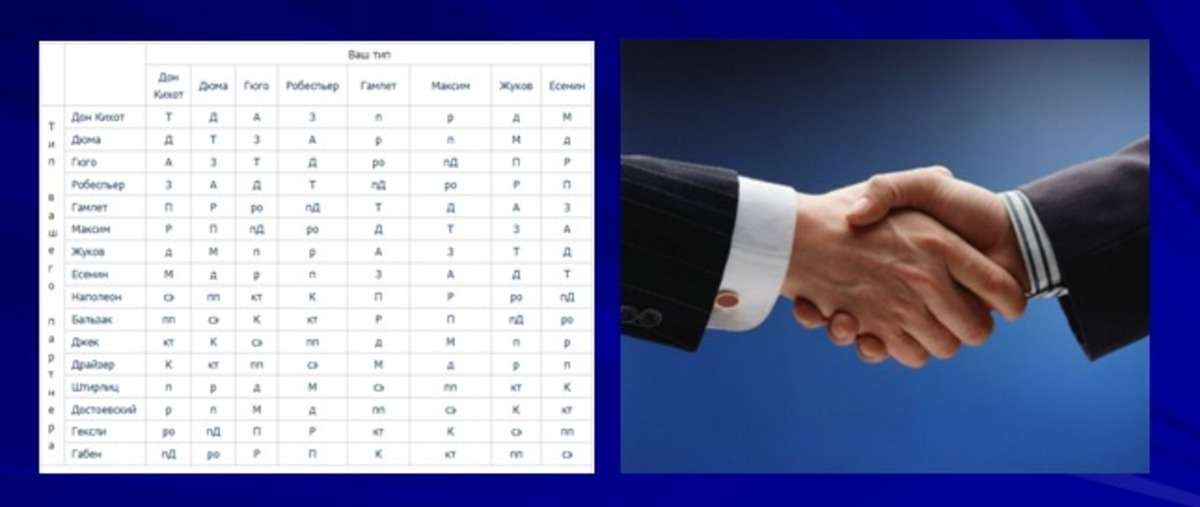
Расскажу для начала для непосвященных: соционика – это наука о типах людей и отношениях между ними. Типов в соционике всего 16, и для каждого типа есть свой, единых тип, который дуален ему. Отношения симметричны: каждый дуал дуален другому дуалу. У социотипов есть псевдонимы: Дон Кихот, Дюма, Гюго, Робеспьер, Гамлет, Максим, Жуков, Есенин, Наполеон, Бальзак, Джек, Драйзер, Штирлиц, Достоевский, Гексли, Габен.
Источником вдохновения этого дела были эксперименты по знакомству соционических дуалов. О том, насколько хороши дуальные отношения более подробно рассказывает Шульман в статье:
Ода дуальному контакту https://isocionics.com/library/shulman
От себя же скажу: дуалы притягивают друг друга. Людям с дуалами хорошо, и они проявляют себя в принципиально новых качествах, чем они были до этого. Поднимается положительная энергия и даже в некоторых случаях рождается любовь. Мой личный опыт знакомства множества дуалов это подтвердил.
По сути, дело я имею дело с формулой любви, и я хочу подарить людям возможность применить ее для себя.
Более подробно, об экспериментах с соционическими знакомствами изложено здесь:
https://isocionics.com/goodness
Соционика рекомендует строить семьи на основе дуальных отношений, и 2 семьи уже успешно созданы (в том числе - моя), и я хотел бы этот успешный результат растиражировать в бесчисленное число раз. Преградами для реализации этого плана является сильная неравномерность распределения типов людей из-за чего подобрать дуала становиться очень сложно, и нужно типировать порой сотни человек, прежде чем кому-то повезет найти дуала.
 Я хочу сделать процесс
типирования простым, дешевым и доступным. Для этого я и начал разрабатывать СОЦИОМЕТР
Я хочу сделать процесс
типирования простым, дешевым и доступным. Для этого я и начал разрабатывать СОЦИОМЕТР

Ядром работы программы СОЦИОМЕТРА был калькулятор ПР(Признаков Рейнина) разработанный мною и моей командой для оценки точности распознавания соционического типа.
Этот калькулятор был лучшей разработкой среди калькуляторов ПР в соционическом мире тк единственный, который правильно делает расчеты с точки зрения принципов теории вероятностей.
Подробнее про калькулятор можете узнать здесь: https://isocionics.com/library/reinin_dichotomy/reinincalc
Видео гайд по калькулятору ПР.

И вот наступила потребность вооружить его четкимикритериями для выставления конкретных оценок точности для распознавания дихотомий и как следствие – сделать его инструментом для распознавания соционического типа.

Желание найти дуалов как можно большему числу людей. Возможность распознавать социотип быстро, просто и качественно. Возможность свести как можно большее число дуалов. Сделать так, чтобы каждый смог найти свою вторую половинку настолько быстро насколько это в принципе возможно.
Простота использования, большой анализ данных, возможность определить свой тип, и тип любого, кого захотят пользователи, возможность найти свою вторую половинку с помощью СОЦИОМЕТРА, а также много других применений соционического типа (изложенного выше)
Все русскоязычные от 14 лет.
Наш калькулятор ПР, в основе которого лежит СОЦИОМЕТР является лучшим в мире среди калькуляторов ПР т.к. он на текущий момент единственный среди социоников, который делает математически правильные расчеты с точки зрения принципов теории вероятностей. Подробнее, почему это так – изложено в статье (см снизу)
https://isocionics.com/library/reinin_dichotomy/reinincalc
Ранее были попытки создать программу распознающей соционический тип, но очень мало кого заботил вопрос о качестве исходных данных, что приводило к тому, что впоследствии программы выдавали «странные результаты»
Наш проект в первую очередь нацелен взять за основу только отипированных с максимально высокий качеством людей путем личного интервью с каждым человеком(даже если он итак знает свой социотип!) и тщательной проверкой.
Также, в ходе проверки будут использованы интертипные отношения между типируемым и диагностом – чего не проводят конкуренты, чтобы получить на выходе программу, которая максимально точно распознавала бы социотипы
Что в данный момент сделано:
Отипировано 124 человека в лучшем качестве. С каждого было взято видео по 1 часу. Первые 45 минут общения превращены в текст. Полученные тексты были обработаны статистическими программами и были выявлены закономерности предпочтения тех или иных слов(частоты) применительно к признакам Рейнина.
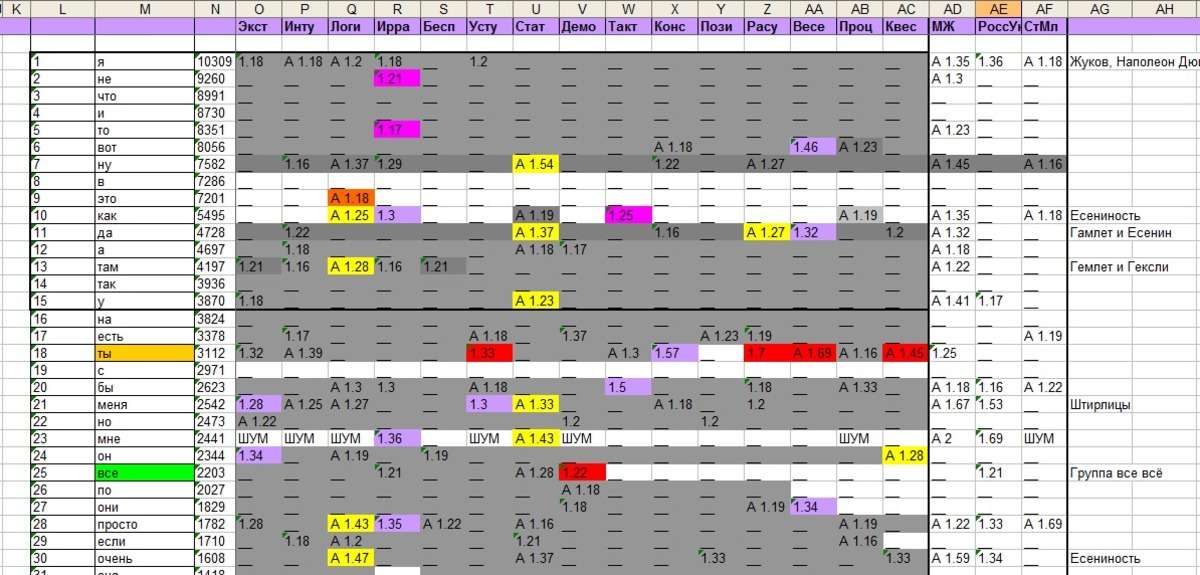
Все слова суммировались по количеству и упорядочены по убыванию – столбец М – слова, столбец N - количество. Первая строка выделенная фиолетовым в этой таблице – это дихотомии Рейнина – взято первая полярность первые 4 буквы названия. Например «Экст» – Экстраверсия, «Инту» – это Интуиция, и так далее.
Фиолетовым в таблице значений – отмечено преобладание со стороны первой полярности дихотомии. Например слово «вот» 1,46 в столбце «Весе» означает что Веселые используют слово «вот» в 1,46 раза чаще чем противолопожная полярность Серьезные.
Желтым выделено числа с приставкой «А» означает «Антиполярность» то есть признак, который контрастно проявился у людей с противоположной полярностью
Например: слово «как»в столбце «Логи» А 1,25 означает что у противоположной полярности Логике тоесть Этике, или у Этиков слово «как» используется в 1,25 раза чаще чем у Логиков.
Серым, отмечены те параметры, которые по каким-то причинам были отвергнуты: то ли из-за противоречивого набора дихотомий, то ли из-за того что расчеты по критерию Стьюдента показали слишком малое значение.
Красным отмечены значения, которые были отвергнуты из-за того, что было очевидным что данное слово используется не потому что это типное слово, а под влиянием других причин. Так, например слово «Ты» используется не потому что какие-то типы склонны чаще «тыкать» а по причине того, что в процессе беседы находился в неформальной психологической дистанции. Слово «все» было отвергнуто из-за погрешности наборщиков текста: одни набирали «все», другие набирали «всё», поэтому данное слово было отвергнуто.
В таблице еще встречаются такие понятия как ШУМ. Это означает, что доминанта данного слова в пределах данной дихотомии существует, но на самом деле это был результат доминанты другой дихотомии.
В таблице также присутствуют такие столбцы как МЖ, РоссУкр, СтМл – это дихотомии не относящиеся к соционическим, целью которых отфильтровать признаки не имеющие отношения к соционическим.
МЖ – мужчины/женщины
РоссУкр – так получилось что у меня типируемые были либо из Украины либо из России. Так и получилась эта дихотомия.
СтМл – Старшие/Младшие. Было за основу взято деление так, чтобы поделить отипированных по возрастному критерию пополам. Это был возраст 35 лет: кто старше был отнесен к старшему, кто младше был отнесен к младшим.
Итак, вот какие доминанты в речи в рамках этих дихотомий показала программа «Анализатор Доминант»

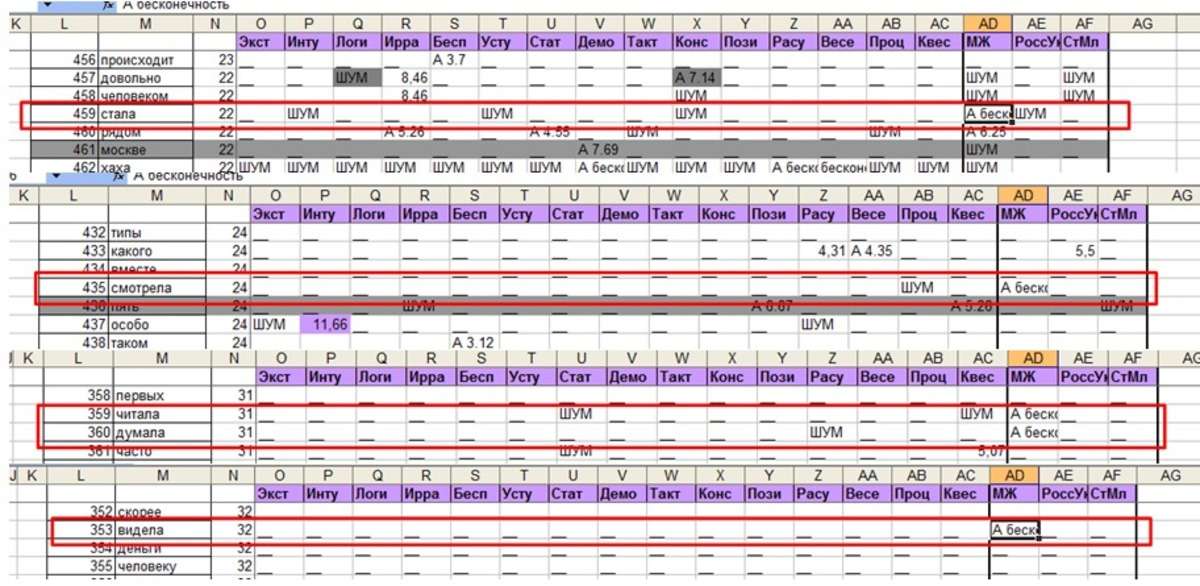
Если говорящий высказал такие слова как: «муж, согласна, хотела, стала, смотрела, читала, думала, видела» – значит, можно утверждать, что говорящий с вероятностью более чем 99% - женщина!
Мои статистические исследования это доказали.

Юмор состоит в том, что потенциально можно выпустить версию программы, которая будет распознавать на основании текста: вы мужчина или женщина, Вы из Украины или России, вы младший или старший.
Как правило, это итак очевидные вещи, но, то, что программа может это вычислять это немного забавно. Тем не менее, я включил этот пункт в описание проекта, потому что хочу продемонстрировать что программа МОЖЕТ ВИДЕТЬ РАЗЛИЧИЕ МЕЖДУ ЛЮДЬМИ, и в частности различие между дихотомийными признаками.
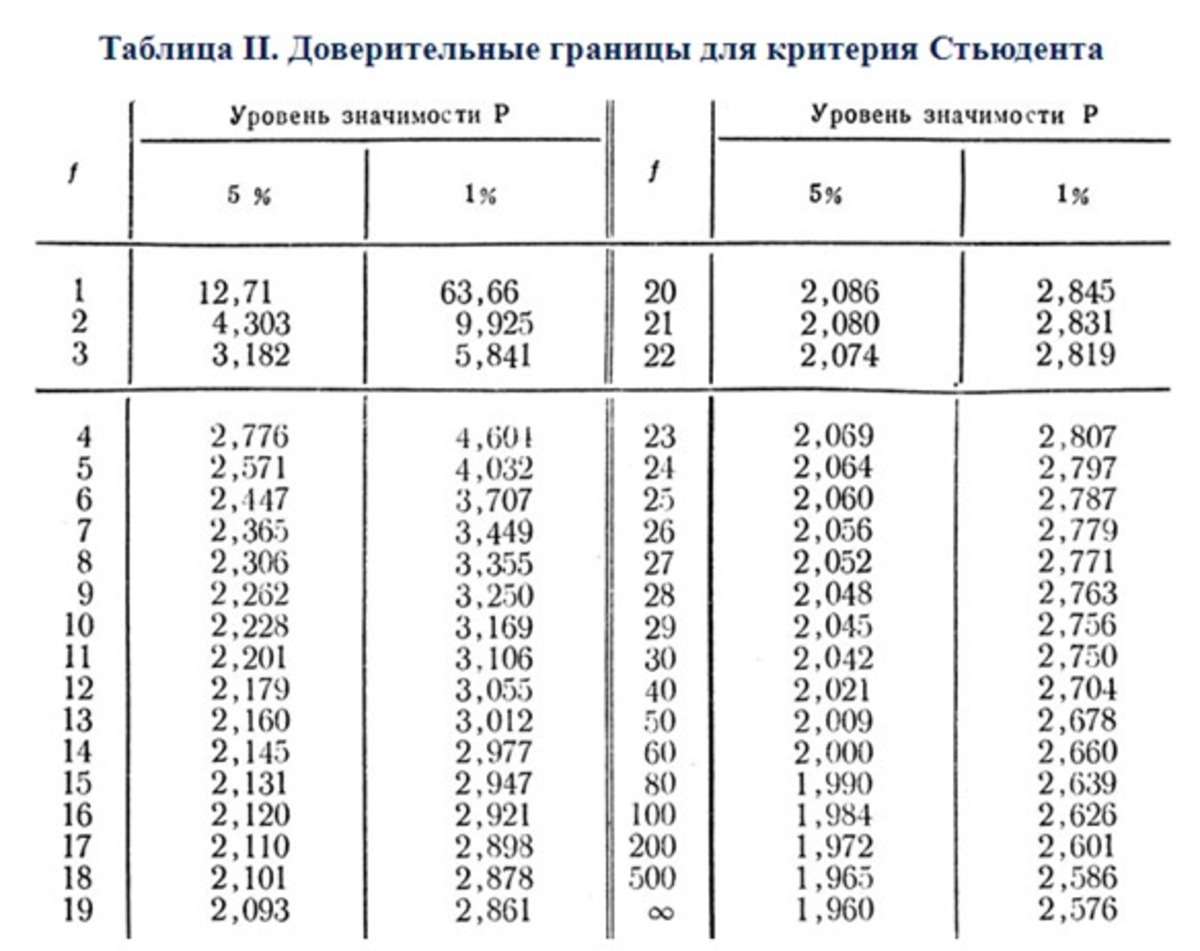
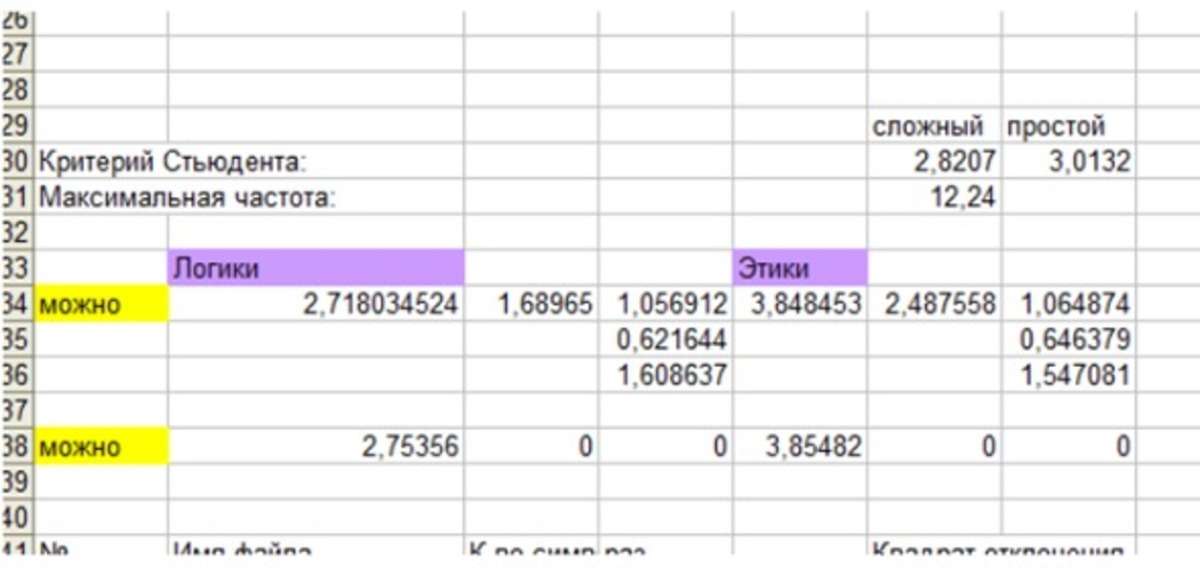
На слайде выше приведен пример расчета частоты использования слова «можно» Логиками и Этиками с использованием критерия Стьюдента:
2,71 – это частота, которая использовалась в среднем Логиками в течении 45 интервью
1,68 – среднеквадратическое отклонение для Логиков
3,84 – это частота, которая использовалась в среднем Этиками в течении 45 интервью
2,48 – среднеквадратическое отклонение для Этиков
Критерий Стьюдента рассчитанный двумя способами:
Сложный: 2,82
Простой: 3,01
- Используются оба способа т.к. выборка при различных способах деления получается не всегда равномерной.
Вторая строка для слово «можно» со значениями описывает расчеты для случая, если бы мы имели бы дело с экспоненциальным распределением – что это такое? – Вот примеры:
Нормальное распределение:
Экспоненциальное распределение
Эти частотные параметры были введены в программу именуемую "СОЦИОМЕТР" и таким образом на основании частот тех или иных слов программа вычисляет вероятность определения конкретного признака Рейнина а вместе с тем распознает соционический тип
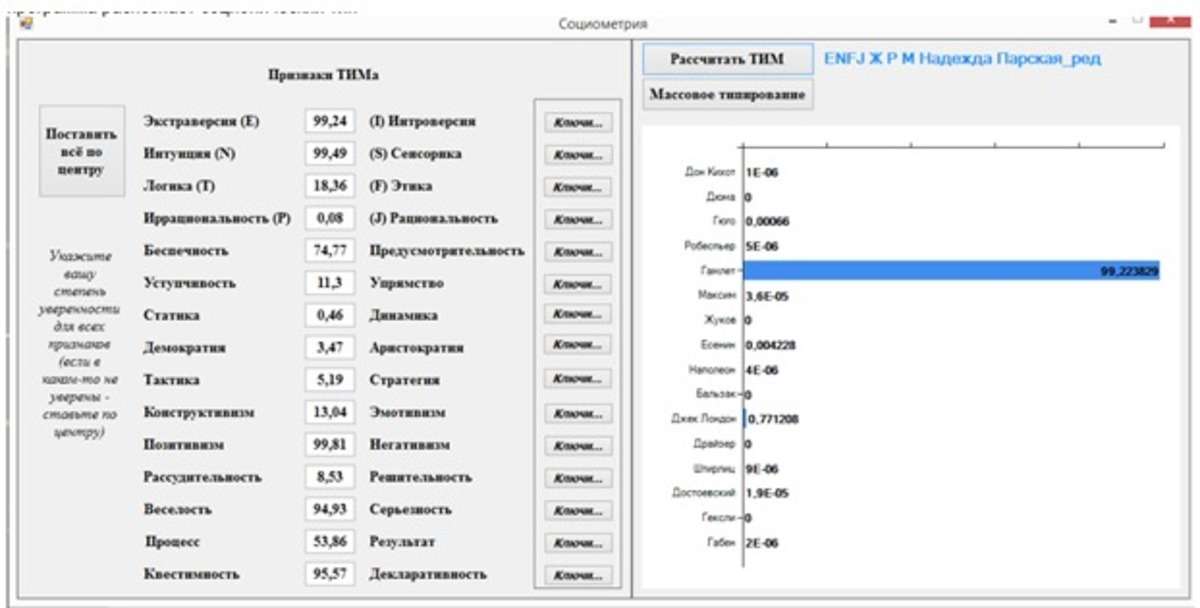
Нажав на кнопку «Рассчитать ТИМ» - открывается окно загрузки текстового файла, и, анализируются частотные параметры слов человека, затем распознается соционический тип.
Кнопка «Массовое типирование» - позволяет отипировать всех, кто находиться в заданном каталоге. Результат массового типирования выводиться в этот файл. Эта функция позволяет в общем и в целом оценить работу программы
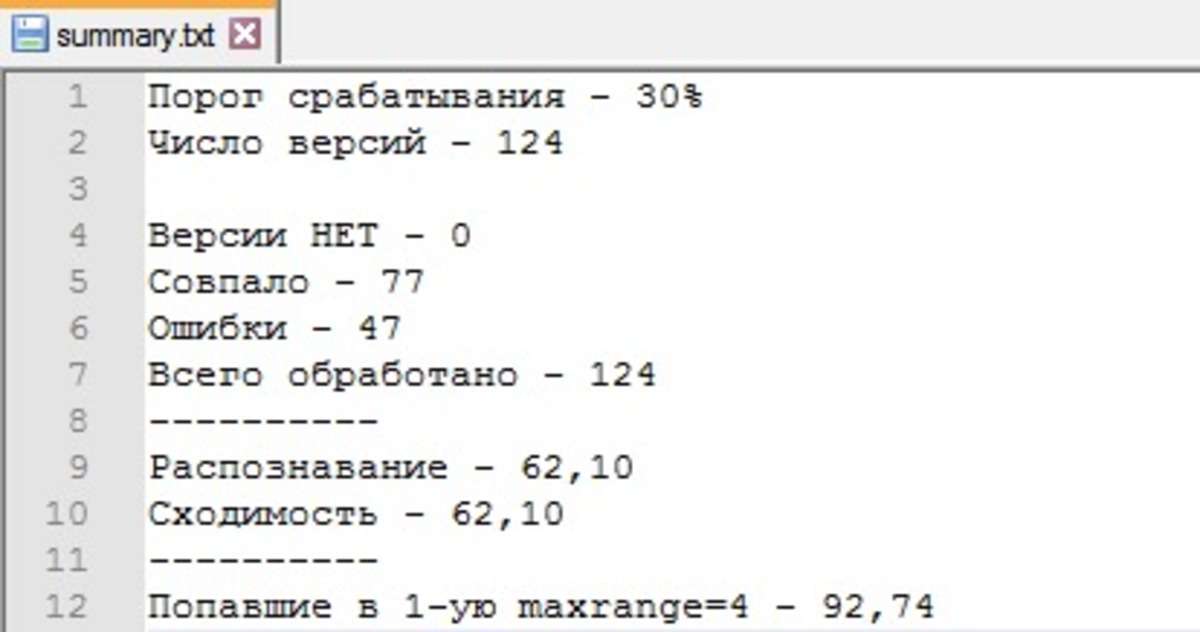
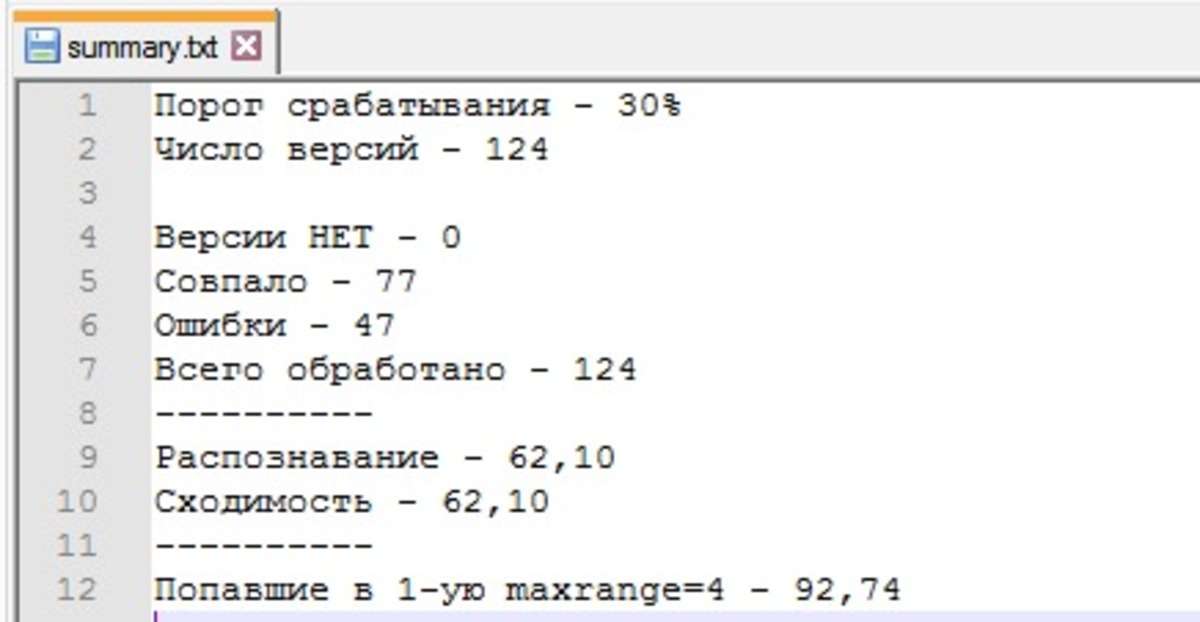
ПОРОГ СРАБАТЫВАНИЯ – уровень уверенности программы, ниже которой она будет считать, что ВЕРСИИ НЕТ. На данном слайде этот параметр равен 30%
ЧИСЛО ВЕРСИЙ – сумма параметров СОВПАЛО и ОШИБКИ
На данном слайде этот параметр равен 124
ВЕРСИИ НЕТ – число версий, ниже порога срабатывания
На данном слайде их 0 потому что выставлен низкий порог срабатывания 30%
СОВПАЛО – программа читает название файла, в котором тип уже указан и сравнивает со своим выводом.
На данном слайде он составляет 77
В имени файлов отипированных есть приставки например:
ENFJ Ж Р М Надежда Парская_ред.txt
ENFJ – код социотипа Гамлет в системе MBTI
Это означает, что Надежда была ранее отипирована в Гамлеты. Программа читает эту приставку и сравнивает свою версию с моей версией(т.е. экспертной) и делает вывод: правильно ли отипировала программа или ошибочно.
Ж – Женщина
Р – Россия
М - Младшая
Про систему наименований MBTIможете почитать здесь https://isocionics.com/library/types_terms
ОШИБКИ – программа читает название файла, в котором тип уже указан и сравнивает со своим выводом.
На данном слайде их 47
ВСЕГО ОБРАБОТАНО – всего файлов. На слайде их 124
РАСПОЗНАВАНИЕ: СОВПАЛО/ВСЕГО ОБРАБОТАНО
СХОДИМОСТЬ: СОВПАЛО/ЧИСЛО ВЕРСИЙ
Попавшие в 1-ую maxrange=4 – 92,74
Программа сравнивает заявленный в названии файла тип. Затем все версии, которые выдвинула программа упорядочивает по убывающей уверенности. Если версия, которая была заявлена оказалась первой четверке в списке (maxrange=4) то программа прибавляет к этому параметру 1. После того, как обработаны все версии, программа полученное количество делит на «всего обработано».
Этот параметр был задуман для того, чтобы отследить характер ошибок программы, и, в том случае, если у Вас вызывают сильные сомнения выдвинутая версия – программа может Вам предложить наиболее вероятные альтернативы.
Программа сформирует log файл с отсортированными по вероятностям версии
Параметр: попавшие в 1-ую maxrange=4 – 92,74 означает, что с вероятностью 92,74% Ваша версия типа находиться в списке первой четверки. То есть:
если программа не сможет отипировать правильно(выбрать доминирующею версию), то по крайней мере она сможет подсказать где искать.
Параметры maxrange= « », Порог срабатывания, а также частотные характеристики слов имеются в файле конфигурации keys.txt
Вы можете установить их по своему усмотрению
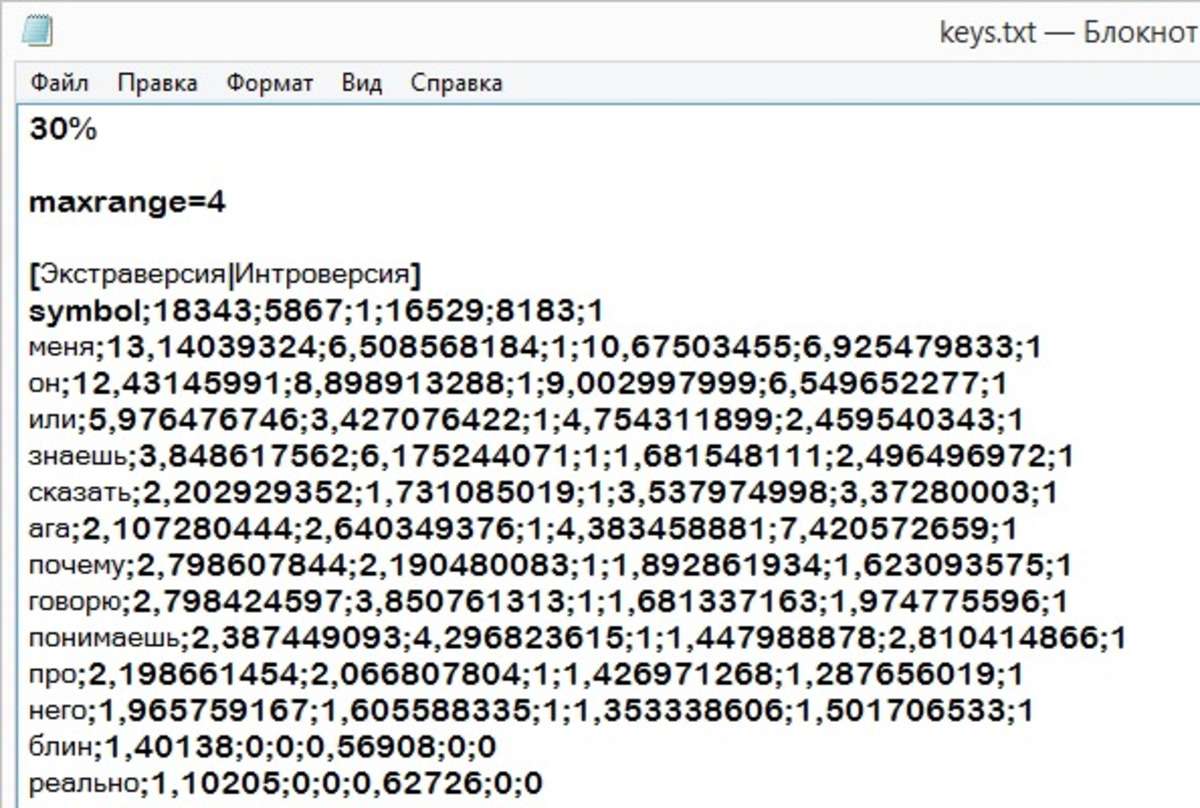
Сейчас программа распознает в 62% случаев
Я хотел бы довести этот показатель до 90% и более
С какими проблемами я столкнулся:
Текущая версия социометра использует слова, убывающие по частоте до 220 слова
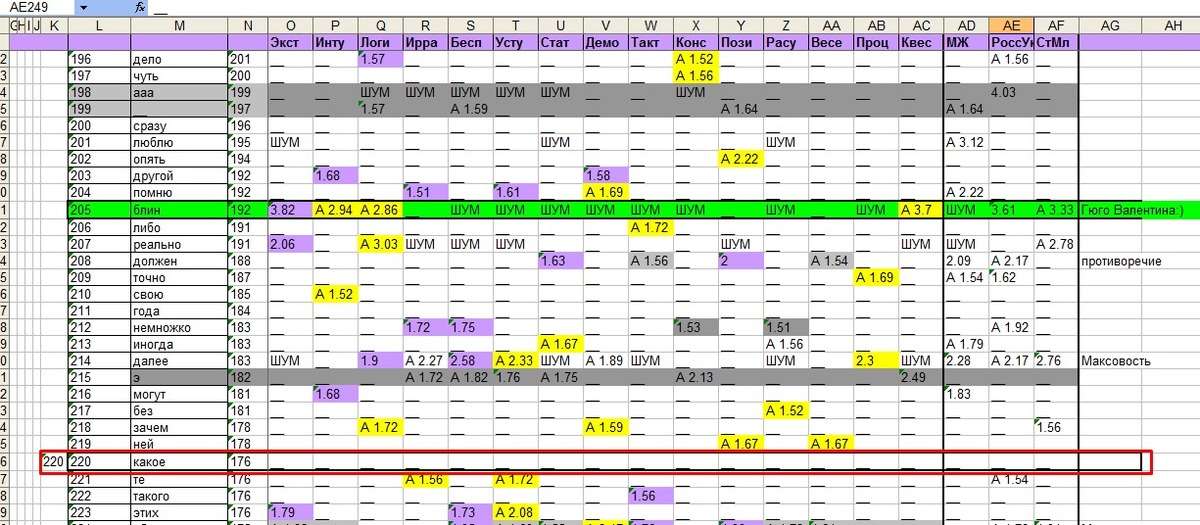
Я знаю, что если пойти ниже и начать использовать другие слова - возникнет проблема "переобученности системы" тоесть: я могу заставить свою программу типировать с большей сходимостью, но нет гарантии что с такой же сходимостью будут типировать всех остальных людей.
Я хочу отипировать еще 200 человек, и также само обработать их своими программами.
Я уверен, этого будет достаточно, чтобы довести параметр «Сходимость результатов» до 90% и более процентов. Благодаря этой программе, каждый ее обладатель сможет узнать типы людей столько сколько ему захочется, с точностью описано ранее, применив соционику описано выше.
Мне, чтобы качественно отипировать человека требуется 3 часа времени на интервью и 3 часа на дальнейшую обработку результатов(анализ видео, поиск возможных альтернатив диагноза типирования, критическое осмысление результатов)
Исходные видео, с 124 человеками я собирал 7 лет. Но потенциально можно сделать 200 за 1 год.
Реальность нынче такова, что у меня есть много желающих потипироваться и очень мало, согласных платить за это деньги.
Я хочу от Вашей платформы, чтобы она выступила третьей стороной в этом деле. Я хочу оплату за свой труд на уровне психотерапевта 1500 руб/час. Или 9000 за типирование человека + 1000 руб за перевод речи в текст, то есть 10000 руб.
Вот полная смета стоимостей работ:

Впоследствии, данная программа сможет резко снизить себестоимость типирования: по сути, нужно будет видео человека, который общается с кем-то: выделить его текст и загрузить в программу.


1 год с момента подачи проекта.
Общаетесь на произвольную тему с другом. Важно чтобы длина общения превзошла 45 минут. Потом превращаете все в текст.
Превращая все в текст – помните, что нужно идеально точно превращать слово-в-слово в ущерб всякой грамматике. Лучше воспользоваться услугами наших наборщиков и корректоров – чтобы максимально точно превратить видео в текст (по этому поводу свяжитесь со мной!).
Затем, удаляете текст собеседника, оставляете текст того, кого хотите отипировать(себя или собеседника). Затем в формате txt загружаете в СОЦИОМЕТР, нажав на кнопку «Рассчитать ТИМ» - СОЦИОМЕТР выдаст Вам результат.
Для 15-минутного интервала используйте СОЦИОМЕТР-15-100 по той же логике
В данный момент себестоимость перевода речи 45 минут в текст стоит 1000 руб, но в перспективе(а это уже не за горами!), когда будет широко доступна технология перевода речи в текст с распознаванием говорящих себестоимость снизится почти до нуля.
Всем отипированным рекомендую вступить в сообщество https://vk.com/iss_socionics_group
и написать о себе тут https://vk.com/topic-115957482_37363788
Вы можете для теста, понять как работает программа нажмите на кнопку «Рассчитать ТИМ», затем залезьте в папку «Тексты отипированных», выберите кого-нибудь и увидите, как программа рассчитает ТИМы.
Для массового типирования – просто выберите эту же папку. Тогда программа сформирует log папку, в которой будет показано куда она отипирует всех людей. Также в ней будет файл summary.txt, который надо открывать программой Notepad++ в которой будет показана общая статистика типирований
Еще нюанс: в имени файлов отипированных есть приставки например:
ENFJ Ж Р М Надежда Парская_ред.txt
ENFJ – код социотипа Гамлет в система MBTI
Это означает, что Надежда была ранее отипирована в Гамлеты. Программа читает эту приставку и сравнивает свою версию с моей версией(т.е. экспертной) и делает вывод: правильно ли отипировала программа или ошибочно.
Ж – Женщина
Р – Россия
М - Младшая
Про систему наименований MBTI можете почитать здесь https://isocionics.com/library/types_terms
Данная разработка будет предложена крупным компаниям, бюджетным организациям, владельцам соц сетей, сайтам знакомств и трудоустройства. Когда социометр достигнет сходимости 90% и более – появиться возможность типировать людей массово, а не поодиночно.
Имея сходимость 90% и более можно будет впоследствии конкретизировать типологию, и углубить ее подтипами.
Эти подтипы впоследствии будут влиять на сферу деятельности человека и смогут более детально прогнозировать отношения. Данная опция будет доступна, когда будет отипировано от нескольких тысяч человек.
Имея в базе данных несколько тысяч человек можно будет сделать СОЦИОМЕТР самообучаемым:
Один раз, настроив СОЦИОМЕТР на распознавание соционических типов со сходимостью от 90% и выше. В случаях уверенности СОЦИОМЕТРа более 99% в соционическом типе, СОЦИОМЕТР сохраняет параметры речи человека, и корректирует под него свои параметры, с учетом параметров текущей базы данных.
Таким образом, СОЦИОМЕТР будет постепенно мутировать, подстраиваясь под медленные языковые изменения людей. Мутацию можно настроить как в автоматическом режиме(описано выше) так и в ручном: когда в соционическом типе уверен типировщик.
Уточнить семантику информационных аспектов
https://isocionics.com/library/aspects
Исследовать: какие слова из семантики информационных аспектов используются людьми чаще всего
Оторваться от контента и использовать только видео
Когда натипируем несколько десятков тысяч людей можно будет впоследствии оторваться от контента и перейти к анализу видео, которое будет улавливать малейшие движения человека - и примерно за 5 мин будет угадывать его социотип. При этом даже не важно, что он говорит, на каком языке говорит и с кем говорит. Вот кстати одна из моих разработок в сфере видео, где показывается как легко синхронизируются люди(не просто похожи своим поведением а ведут себя синхронно ), представители социотипа "Жуков"
Данное видео показывает возможность существования некоторого "диапазона" в котором движется человек конкретного типа.
Хочу также предложить Вашему вниманию еще один величайший эксперимент в области самотипирования, который я провел с помощью СОЦИОМЕТРА 1го июля 2023 года
103 интервью по 45 минут!
11 лет сбора видео данных!
200 ключевых слов для анализа!
Сходимость 87%!!!
Суть: я мерил сходимость своего СОЦИОМЕТРА с самой обучаемой выборкой. Она составила 60%. Интересным будет померить сходимость с другой выборкой: не обучаемой. Что у меня есть? Дело все в том, что большинство интервью было проведено мною, и там есть мои тексты. Когда обучал свой СОЦИОМЕТР то использовал тексты только тех, кого отипировал. Свои же использовал только 6 раз, для того чтобы СОЦИОМЕТР знал что мой соционический тип Робеспьер. Остальные свои тексты из диалогового интервью удалил, оставив лишь те, что наговорили испытуемые для обучения СОЦИОМЕТРа. Я решил сделать обратную операцию: удалил тексты испытуемых, оставив лишь свои. Всего их было 103
Теперь интересно узнать: сколько раз СОЦИОМЕТР УГАДАЕТ ЧТО МОЙ СОЦИОНИЧЕСКИЙ ТИП РОБЕСПЬЕР?
Социометр распознал мой соционический тип в 87% случаев!!!
Это была независимая оценка. Социометр МОЖЕТ ВЫЧИСЛИТЬ МЕНЯ!!!
Хочу подчеркнуть также тот факт что СОЦИОМЕТР не учился на этой выборке, тоесть получено сходимость 87% уже на независимой выборке.


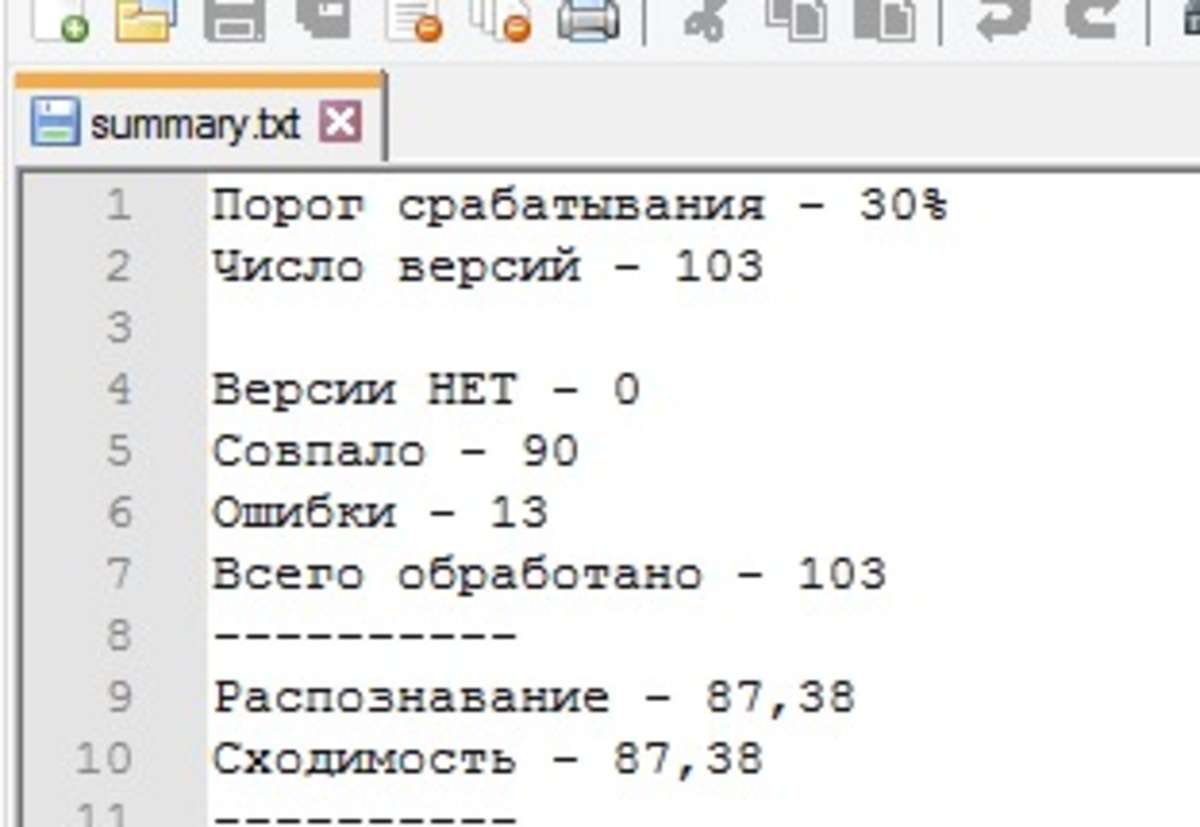
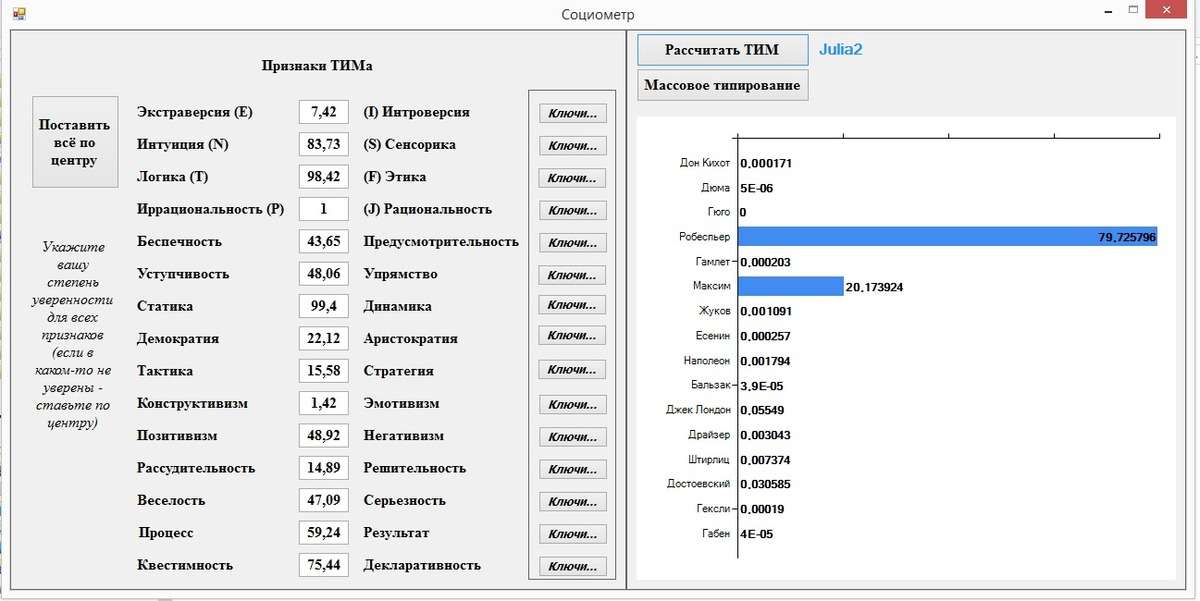
Еще хочу рассказать про 2 своих Эксперимента, в которых я загрузил текст в написанный когда-то мною объемом в 40 страниц в 2006 году, и вот что выдал СОЦИОМЕТР:
Второй Эксперимент – это текст, который я написал для Евгении Казаковой объемом в 45 страниц недавно
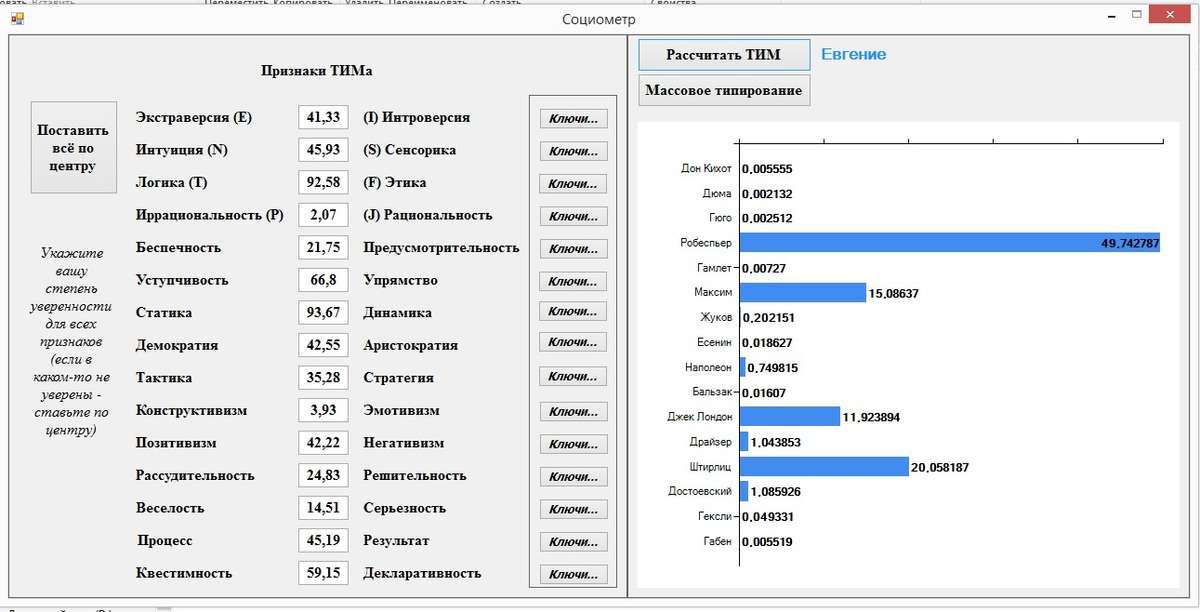
Данный эксперимент дает основания для следующих выводов:
Тем не менее есть нюансы:
3) Данный подход является небольшим отступлением от темы, и требует дополнительных вложений средств, чем то, что ранее рассказано в изначальном описании проекта, но чем больше различных подходов будем использовано – тем больше итоговая точность будет у проекта. Если более конкретно: допустим: мы добудем в 5 раз больше интервью из уже имеющихся людей из базы данных. 5 Раз больше – означат в 5 раз больше затрат на транскрибацию текстов. Или еще 500 тыс руб.